さらに例を見る
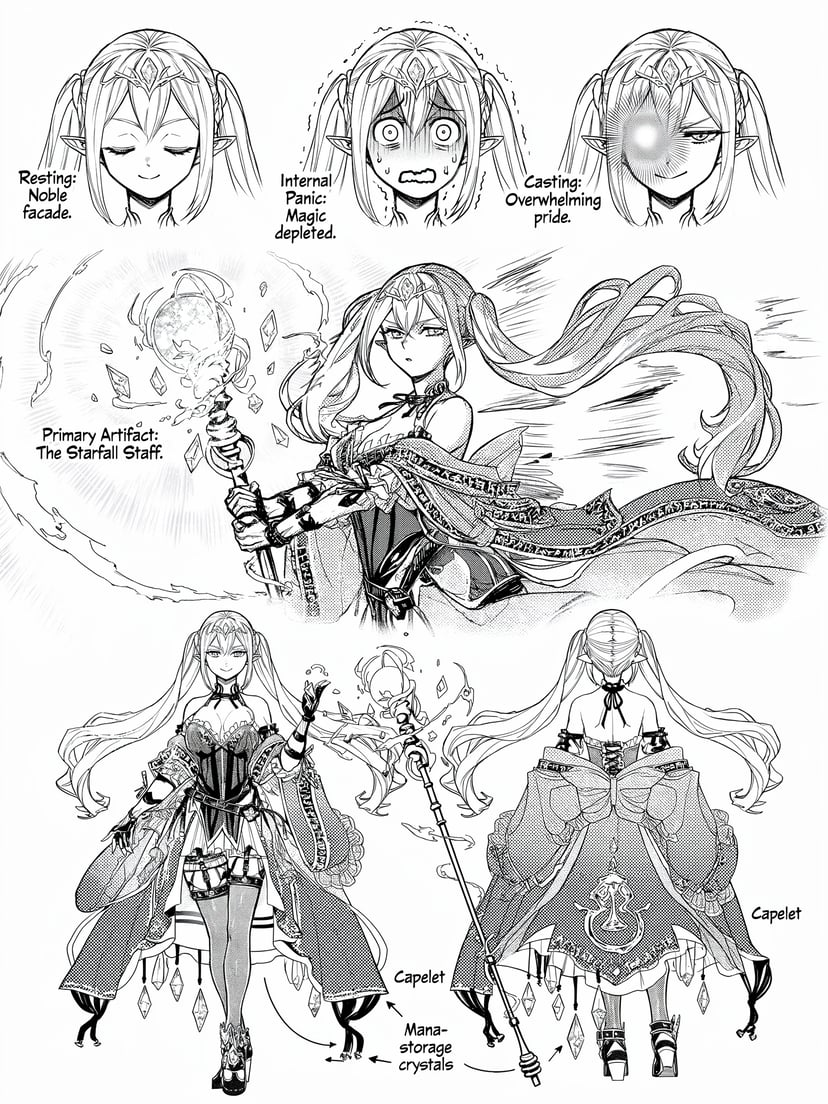
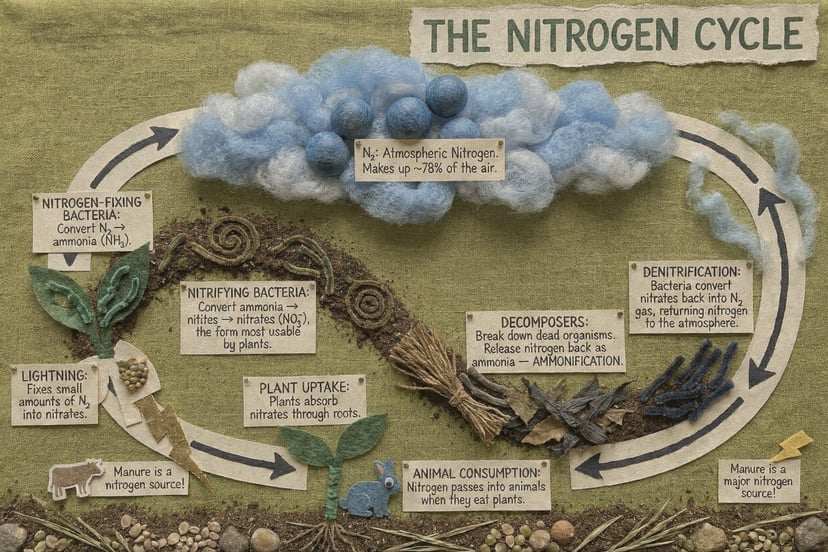
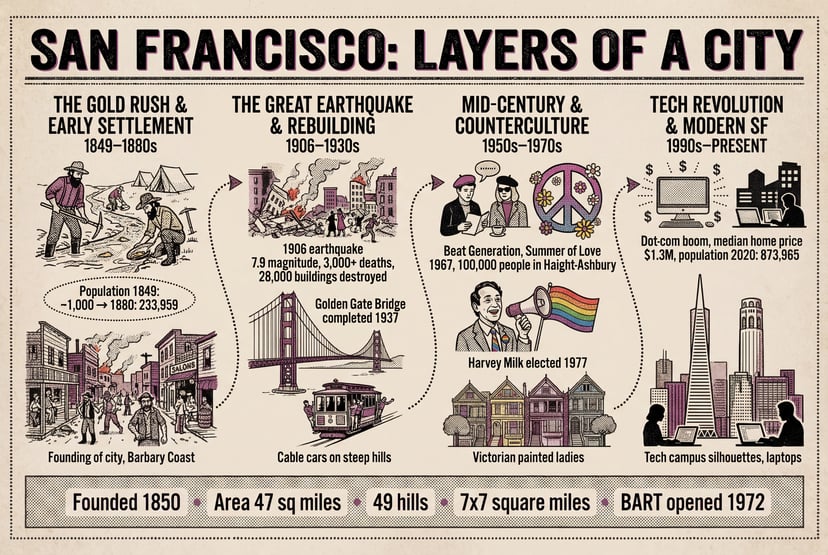
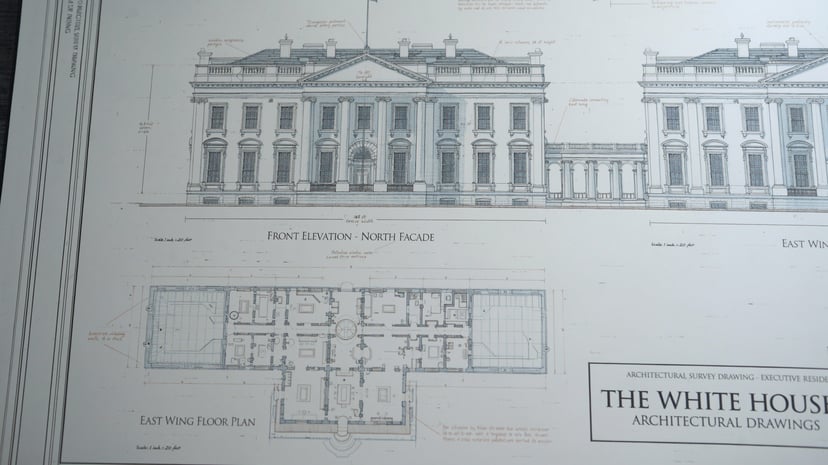
インフォグラフィック、図解、モールス信号、多言語テキストなど — ピクセルより前の構造化された推論。



UNI-1 · 統合インテリジェンス
下に欲しい内容を書く — ワンクリックで生成。
The full studio — generator, examples, and deep content — lives on a dedicated page so this homepage stays lightweight and fast.
プレビュー用です。「生成」でスタジオが開き、プロンプトが入力されます。
Sample look

Illustrative frame. Actual output depends on your prompt and settings in the studio.
Features and availability may vary by region and product updates.
ショーケース
同一モデルの出力です — 上のジェネレーターで自分のプロンプトを試せます。
さらに例を見る
インフォグラフィック、図解、モールス信号、多言語テキストなど — ピクセルより前の構造化された推論。
次の進化
AI画像生成の新パラダイム
2026年に初公開された UNI-1 は、視覚推論と画像生成を単一の統合アーキテクチャに組み込んだ初の主要画像モデルです。
従来のパイプラインは言語モデルと画像生成を別々に繋ぎ、受け渡しごとに文脈が欠けます。UNI-1 はそのギャップを減らし、多ターンの創作をより一貫させます。
画像合成の前後で構造化された内部推論が可能 — 指示の分解、制約の解決、描画前の構成計画まで行います。
常識に基づくシーン補完、空間推論、妥当性のある変換 — プロンプトに従うだけでなく理解します。
複数写真を一つの新しい構図に融合 — 別々のソースから人物・物体・環境を一つのシーンに。
世界の美学、ミーム、マンガなど文脈に敏感な生成 — 汎用モデルが見落とすニュアンスを捉えます。
常識に基づくシーン補完、空間推論、妥当性のある変換 — プロンプトに従うだけでなく理解します。
複数写真を一つの新しい構図に融合 — 別々のソースから人物・物体・環境を一つのシーンに。
一文のプロンプトで、固定カメラ角から幼少から老年までの変化を生成 — 身体的加齢や家族の変化などの因果も自動処理。
文脈を保ったまま複数ターンで調整、76以上のアートスタイル、スケッチや視覚指示の入力、参照からの同一性・ポーズ・構図転送。
世界の美学、ミーム、マンガなど文脈に敏感な生成 — 汎用モデルが見落とすニュアンスを捉えます。
熟語や非ラテン文字を含む複雑な文字をほぼ誤りなく描画 — 多くの競合を上回る精度。
推論系ベンチで Google Imagen 3 や OpenAI GPT Image 1 を上回り、物体検出では Gemini 3 Pro に迫る性能を、高解像度で約10〜30%低コストで実現。
RISEBench で時間・因果・空間・論理の各能力において最先端の結果。
人間嗜好の Elo で総合品質・スタイル編集・参照ベース生成で1位、テキストto画像で2位。
理解のみのバリアントは ODinW-13 で43.9、生成込みのフルモデルは46.2。2.3点の改善は「創ることを学ぶと理解が上がる」ことの証拠であり、統合が性能倍増要因であることを示します。
2K解像度では UNI-1 のテキストto画像が約$0.09/枚、Imagen 3 が$0.101、Imagen 3 Pro が$0.134。
より多くの能力。より低いコスト。妥協なし。
価格はUSD。課金トークンに基づく。各画像(入出力)= 現行設定で2,000課金トークン。
単一のブリーフからテキスト・画像・動画・音声を協調する現代的なスタックは、共有空間で言語と画像トークンを交差するデコーダのみの UNI-1 に基づき、モデル連鎖なしで動きます。
Google Veo 3、ByteDance Seedream、ElevenLabs 音声モデルなど、他のフロンティアモデルと連携しながら計画・生成します。
実例:1年・$1,500万の国際キャンペーンを約40時間で多国向け低コスト版に — 厳格な社内QCを通過。
世界の主要ブランドに採用:
Publicis Groupe、Serviceplan、Adidas、Mazda など — 代理店規模の制作に。
従来の拡散にとどまらず純粋な自己回帰統合パラダイムを採用。GPT系と整合する純デコーダ Transformer。
テキストと画像を単一の交錯列として扱い入出力の両方に — 合成前後の構造化推論を可能に。
人間の建築家のような直感的創作プロセスに近づけ — 光、空間、構図を同時にシミュレート。
2026年3月5日に発表された統合理解・生成モデル。単一のデコーダのみ自己回帰 Transformer で視覚推論と画像生成を統合。
パターンマッチではなく、生成前後にプロンプトを推論し、計画し、文脈を理解して実行します。
RISEBench(推論に基づく視覚編集)で時間・因果・空間・論理の四領域でリード。
2K API で約$0.09/枚 — 比較可能な Google モデルより10〜30%安価な場合があります。
はい。本サイトで無料テスト可能です。APIは段階的に拡大 — 企業向けはサポートへ。
多参照合成、76+スタイル、マルチターン編集、スケッチto画像、同一性/ポーズ転送、年齢シークエンスなど — すべて統一推論アーキテクチャから。
画像生成の階層は変わりました。UNI-1 は競争するだけでなく、AIの創り方を再定義します。
Unified Intelligence
UNI-1 および関連名称は各権利者の商標である場合があります。本サイトは uni-1ai.com により運営。課金・利用規約・サポートはアプリ内のリンクとメールをご利用ください。