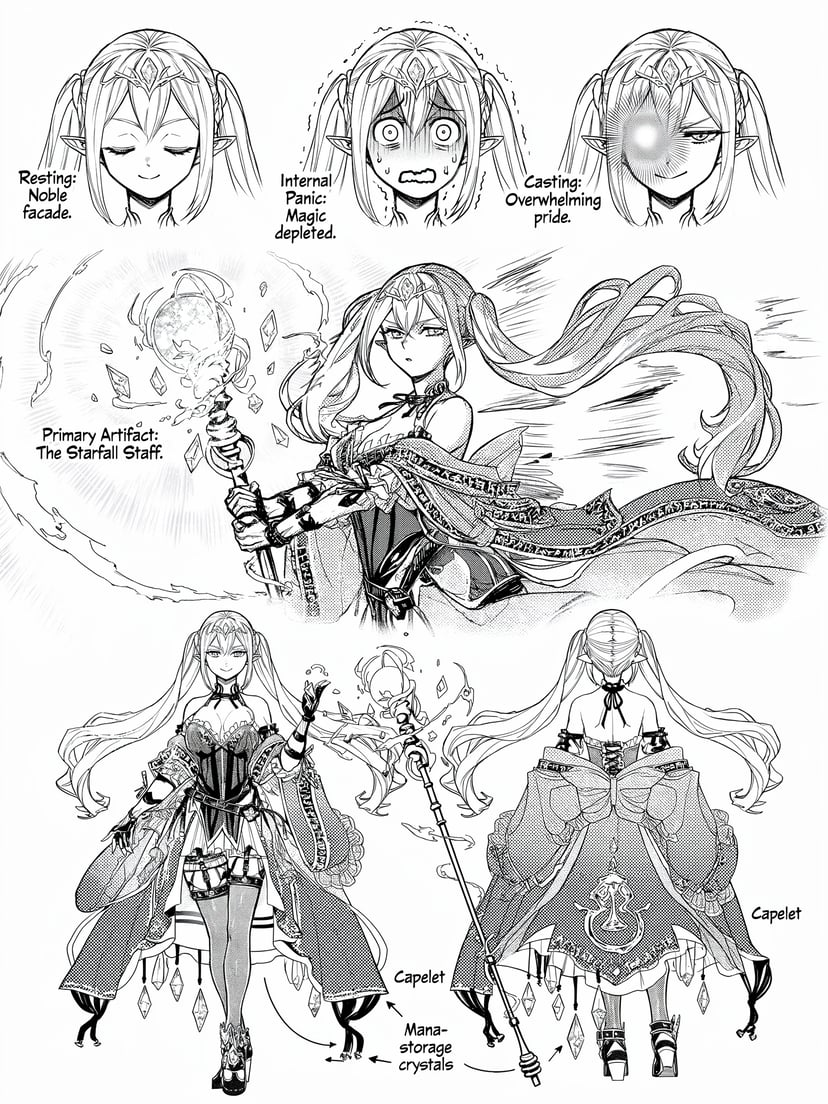
Más ejemplos
Infografías, diagramas, código Morse y texto multilingüe — razonamiento estructurado antes de los píxeles.



UNI-1 · Inteligencia unificada
Describe lo que quieres abajo — genera con un clic.
The full studio — generator, examples, and deep content — lives on a dedicated page so this homepage stays lightweight and fast.
Solo vista previa — Generar abre el estudio y rellena tu prompt.
Sample look

Illustrative frame. Actual output depends on your prompt and settings in the studio.
Features and availability may vary by region and product updates.
Muestra
Salidas del mismo modelo — usa el generador de arriba con tu propio prompt.
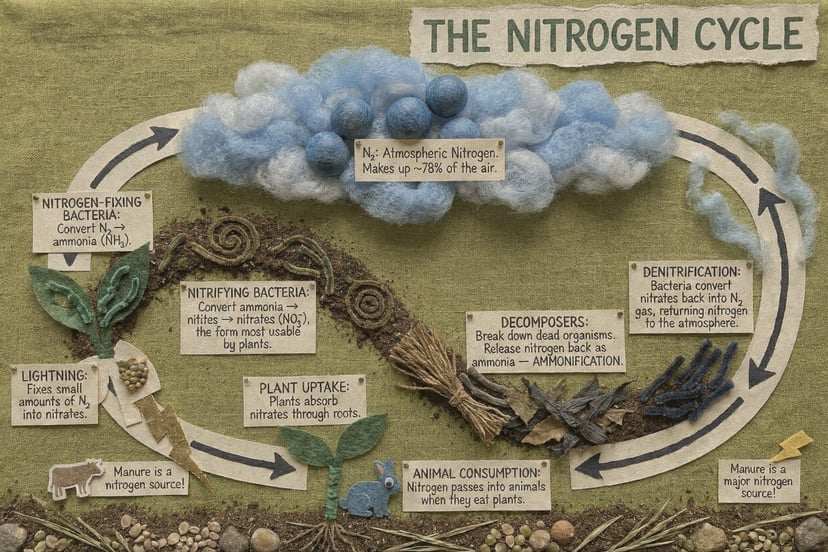
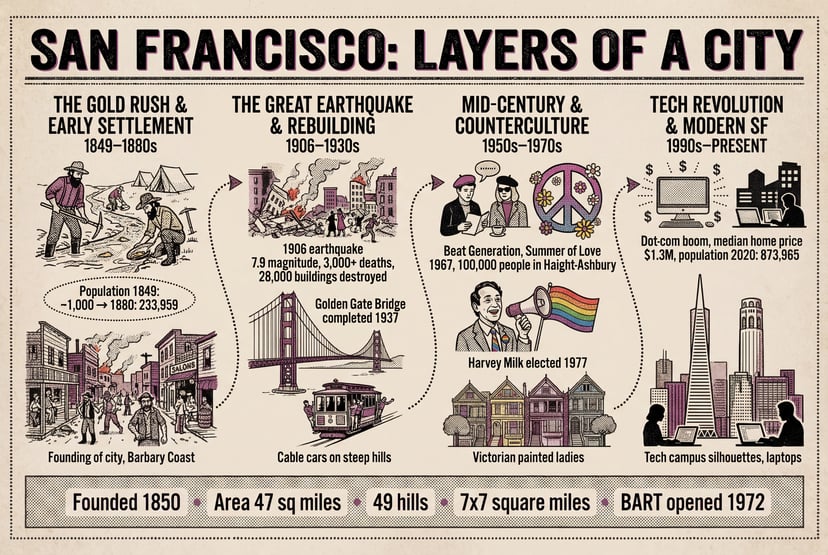
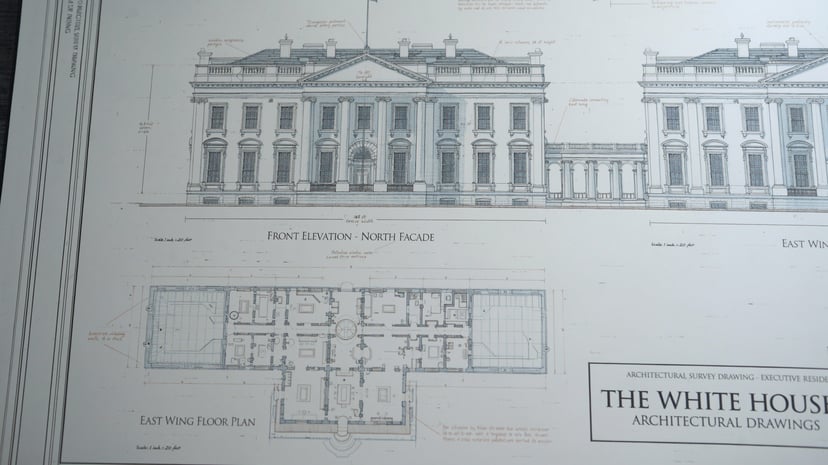
Más ejemplos
Infografías, diagramas, código Morse y texto multilingüe — razonamiento estructurado antes de los píxeles.
La siguiente evolución
Un nuevo paradigma para generación de imagen con IA
Lanzado por primera vez en 2026, UNI-1 es el primer gran modelo de imagen que combina razonamiento visual y generación en una arquitectura unificada.
Los pipelines tradicionales encadenan un LM a un generador separado y pierden contexto en cada paso. UNI-1 reduce esas brechas y permite flujos multironda más coherentes.
Puede razonar de forma estructurada antes y durante la síntesis — descomponer instrucciones, resolver restricciones y planear la composición antes del primer píxel.
Completado de escenas con sentido común, razonamiento espacial, transformaciones plausibles — no solo sigue prompts, los entiende.
Fusiona varias fotos en una composición nueva — retratos, objetos o entornos de fuentes distintas en una sola escena.
Generación sensible al contexto cultural global, memes, manga — matices que otros modelos pierden.
Completado de escenas con sentido común, razonamiento espacial, transformaciones plausibles — no solo sigue prompts, los entiende.
Fusiona varias fotos en una composición nueva — retratos, objetos o entornos de fuentes distintas en una sola escena.
Con una frase, genera la evolución de un personaje de la infancia a la vejez con cámara fija — lógica causal como envejecimiento sin intervención humana.
Refina en varias rondas manteniendo contexto; 76+ estilos; bocetos e instrucciones visuales; transferencia de identidad/pose desde referencias.
Generación sensible al contexto cultural global, memes, manga — matices que otros modelos pierden.
Caracteres complejos, modismos y scripts no latinos con casi cero errores tipográficos — por delante de muchos competidores.
Supera a Imagen 3 y GPT Image 1 en benchmarks de razonamiento, se acerca a Gemini 3 Pro en detección de objetos, con coste ~10–30 % menor en alta resolución.
Estado del arte en RISEBench en capacidades temporal, causal, espacial y lógica.
Primero en Elo humano en calidad general, estilo y edición, generación con referencia; segundo en texto a imagen.
La variante solo comprensión obtiene 43,9 en ODinW-13; el modelo completo con generación 46,2. La mejora de 2,3 puntos demuestra que aprender a crear imágenes mejora entenderlas — la unificación es un multiplicador de rendimiento.
A 2K, el precio API de texto a imagen ronda $0,09 por imagen frente a $0,101 (Imagen 3) y $0,134 (Imagen 3 Pro).
Más capacidad. Menos coste. Sin compromisos.
Precios en USD. Basados en tokens de facturación. Cada imagen = 2.000 tokens con la configuración actual.
Los stacks modernos ejecutan trabajo de extremo a extremo desde un solo brief — texto, imagen, video, audio — sobre UNI-1, un transformador solo decodificador que entrelaza tokens en un espacio compartido sin encadenar modelos.
Planifican y generan en múltiples modalidades coordinando con otros modelos de frontera: Google Veo 3, ByteDance Seedream, ElevenLabs, entre otros.
Caso real: campaña internacional de un año y $15 M transformada en versiones localizadas de bajo coste en 40 horas — con control de calidad interno estricto.
Marcas globales líderes confían:
Publicis Groupe, Serviceplan, Adidas, Mazda — producción a escala de agencia.
Más allá de la difusión clásica — paradigma autorregresivo unificado. Arquitectura Transformer solo decodificador alineada con modelos tipo GPT.
Texto e imágenes en una secuencia entrelazada como entrada y salida — razonamiento estructurado antes y durante la síntesis.
Se acerca al proceso creativo intuitivo de un arquitecto humano — simula luz, dinámica espacial y composición a la vez.
Modelo unificado de comprensión y generación anunciado el 5 de marzo de 2026. Combina razonamiento visual y generación en un transformador autorregresivo solo decodificador.
Razona sobre los prompts antes y durante la generación — no solo empareja patrones; planifica y entiende el contexto.
Lidera en RISEBench en las cuatro dimensiones: temporal, causal, espacial y lógica.
Aproximadamente $0,09 por imagen a 2K vía API — 10–30 % menos que modelos Google comparables.
Sí. Puedes probarlo gratis en este sitio. El acceso API se amplía gradualmente — empresas: contactar soporte.
Composición multi-referencia, 76+ estilos, edición conversacional multironda, boceto a imagen, transferencia de identidad/pose, secuencias de envejecimiento — todo desde una arquitectura unificada.
La jerarquía de la generación de imagen ha cambiado. UNI-1 no solo compite — redefine cómo la IA debe crear.
Unified Intelligence
UNI-1 y nombres relacionados pueden ser marcas de sus titulares. Este sitio lo opera uni-1ai.com. Facturación, términos de cuenta y soporte: enlaces y correo en la aplicación.