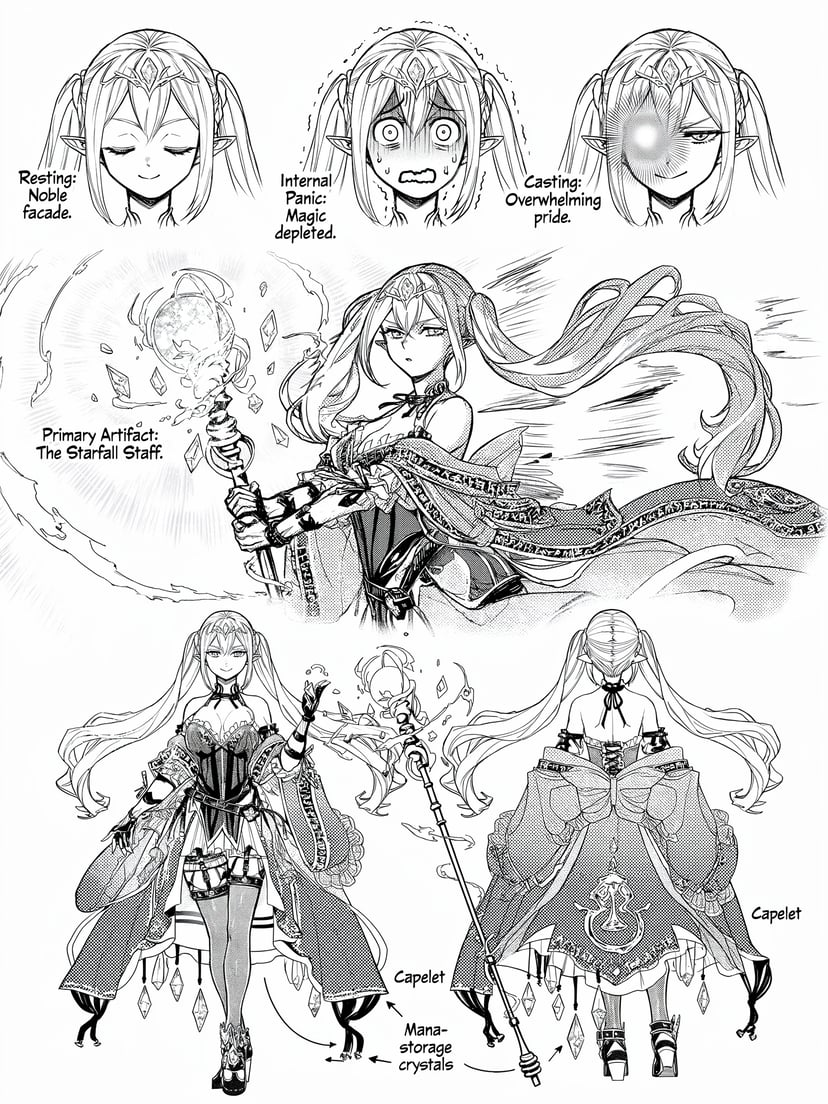
More examples
Infographics, diagrams, Morse code, and multilingual text — structured reasoning before pixels.
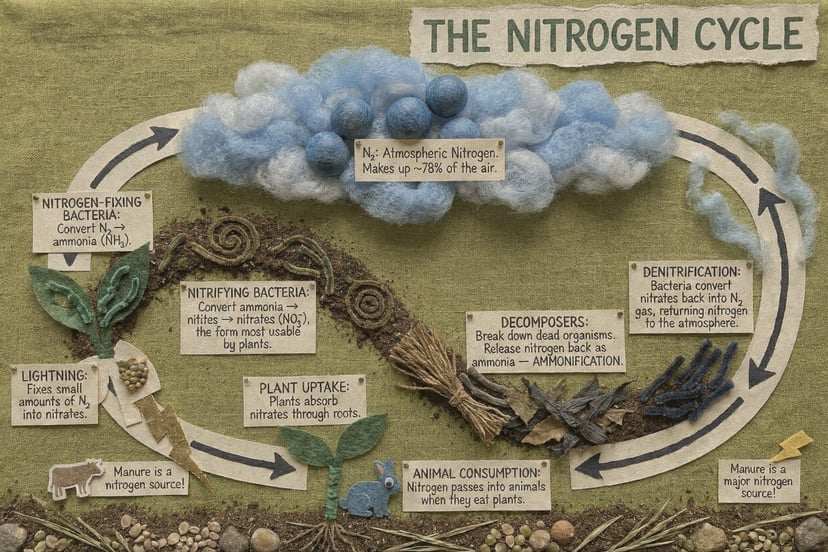
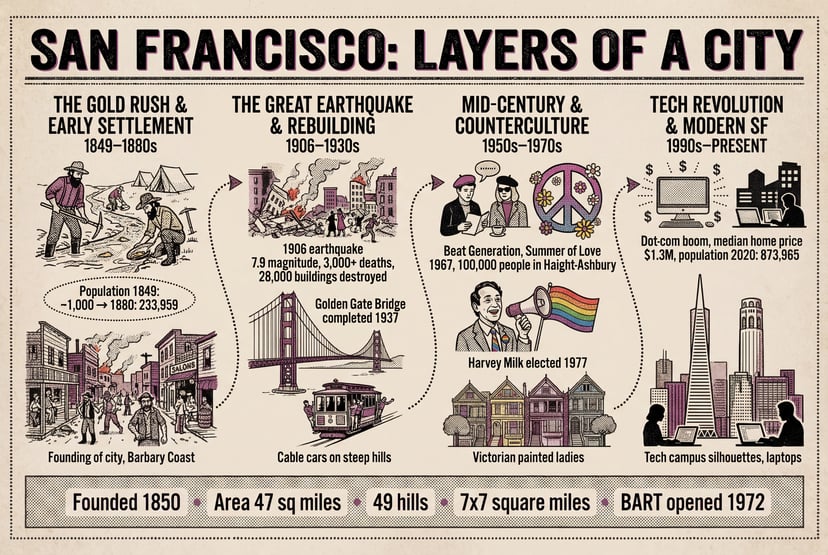
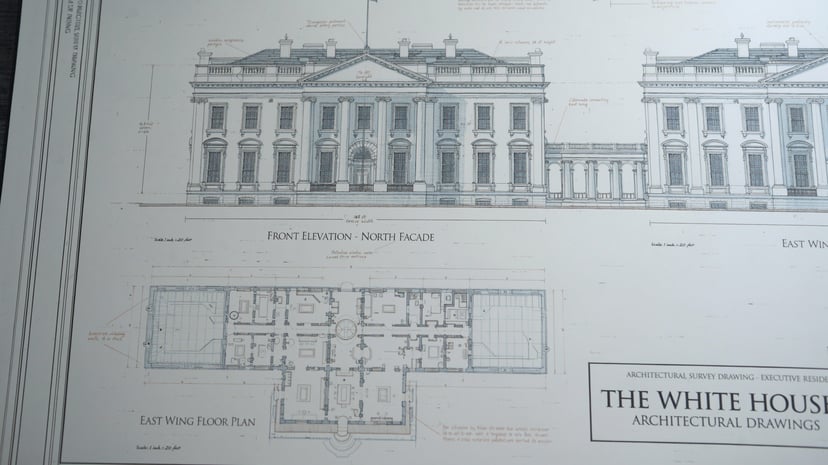



UNI-1 · Unified Intelligence
Describe what you want below — generate in one click.
The full studio — generator, examples, and deep content — lives on a dedicated page so this homepage stays lightweight and fast.
Preview only — Generate opens the studio and fills in your prompt.
Sample look

Illustrative frame. Actual output depends on your prompt and settings in the studio.
Features and availability may vary by region and product updates.
Showcase
Outputs from the same model — use the generator above to try your own prompt.
More examples
Infographics, diagrams, Morse code, and multilingual text — structured reasoning before pixels.
The next evolution
A new paradigm for AI image generation
First released in 2026, UNI-1 is the first major image model to combine visual reasoning and image generation within a single unified architecture — instead of treating understanding and creation as separate problems, UNI-1 handles both with one model.
Traditional AI pipelines chain a language model to a separate image generator, creating context gaps and quality loss at every handoff. UNI-1 eliminates modality gaps common in separate vision and generation systems, enabling more coherent multi-turn creative workflows.
UNI-1 can perform structured internal reasoning before and during image synthesis — decomposing instructions, resolving constraints, and planning composition before rendering a single pixel.
UNI-1 enables common-sense scene completion, spatial reasoning, and plausibility-driven transformation — it doesn’t just follow prompts, it understands them.
UNI-1 can take several photos and merge them into an entirely new composition — combine portraits, objects, or environments from completely separate source images into a single, coherent scene.
UNI-1 delivers culture-aware visual generation across global aesthetics, memes, and manga — understanding nuance and context that generic models miss.
UNI-1 enables common-sense scene completion, spatial reasoning, and plausibility-driven transformation — it doesn’t just follow prompts, it understands them.
UNI-1 can take several photos and merge them into an entirely new composition — combine portraits, objects, or environments from completely separate source images into a single, coherent scene.
With just a single-sentence prompt, UNI-1 generates an evolutionary sequence of a character from childhood to old age under a fixed camera angle — automatically handling causal logic like physical aging and family changes without human intervention.
UNI-1 can refine subjects across multiple conversation turns while keeping context intact, convert images into over 76 art styles, accept sketches and visual instructions as input, and transfer identities, poses, and compositions into new images from reference photos.
UNI-1 delivers culture-aware visual generation across global aesthetics, memes, and manga — understanding nuance and context that generic models miss.
UNI-1 generates complex characters — including Chinese idioms and non-Latin scripts — with virtually no typographical errors, surpassing most competitors in text rendering accuracy.
UNI-1 tops Google’s Imagen 3 and OpenAI’s GPT Image 1 on reasoning-based benchmarks, nearly matches Google’s Gemini 3 Pro on object detection, and does it all at roughly 10 to 30 percent lower cost at high resolution.
UNI-1 achieves state-of-the-art results on RISEBench for reasoning-informed visual editing across temporal, causal, spatial, and logical capabilities.
UNI-1 ranks first in human preference Elo for Overall quality, Style & Editing, and Reference-Based Generation, and second in Text-to-Image.
UNI-1’s understanding-only variant scores 43.9 on ODinW-13 object detection — but the full model, trained with generation, scores 46.2. That 2.3-point improvement is direct evidence that learning to create images makes UNI-1 measurably better at understanding them. This validates the core thesis: unification isn’t just architecture — it’s a performance multiplier.
At 2K resolution — the standard for most professional workflows — UNI-1’s API pricing lands at approximately $0.09 per image for text-to-image generation, compared to $0.101 for Google Imagen 3 and $0.134 for Imagen 3 Pro.
More capability. Less cost. No compromises.
All prices in USD. Per-image prices based on billing token counts. Each image (input or output) = 2,000 billing tokens at current settings.
Modern creative stacks can run end-to-end work from a single brief, coordinating text, image, video, and audio — grounded in UNI-1, a decoder-only transformer that interleaves language and image tokens in a shared space, with no model-chaining required.
These workflows plan and generate across modalities while coordinating with other frontier models — including Google Veo 3, ByteDance Seedream, ElevenLabs voice models, and others.
Real-world results: A 1-year, $15 million international ad campaign was transformed into low-cost, localized multi-country versions in just 40 hours — passing strict internal quality control.
Trusted by leading global brands:
Publicis Groupe, Serviceplan, Adidas, and Mazda — deployed for agency-scale production.
UNI-1 moves beyond traditional diffusion models, embracing a pure autoregressive unified paradigm. It adopts a pure decoder Transformer architecture consistent with GPT-class language models.
UNI-1 represents text and images in a single interleaved sequence, acting as both input and output — enabling structured reasoning before and during image synthesis.
The result is a model that approaches the intuitive creative process of a human architect — simulating light, spatial dynamics, and composition in the mind simultaneously while executing.
UNI-1 is a unified understanding and generation model announced March 5, 2026. It combines visual reasoning and image generation in a single decoder-only autoregressive transformer.
Unlike Midjourney or DALL-E, UNI-1 reasons through prompts before and during generation. It doesn’t pattern-match — it plans, understands context, and executes.
UNI-1 leads on RISEBench (reasoning-informed visual editing) across all four dimensions: temporal, causal, spatial, and logical reasoning.
Approximately $0.09 per image at 2K resolution via API — 10–30% less expensive than comparable Google models.
Yes. You can try UNI-1 free on this site. API access is rolling out gradually — contact support for enterprise options.
UNI-1 supports multi-reference composition, 76+ art style transfers, multi-turn conversational editing, sketch-to-image, identity/pose transfer, and temporal aging sequences — all from a unified reasoning architecture.
The image generation hierarchy has shifted. UNI-1 doesn’t just compete — it redefines how AI should create.
Unified Intelligence
UNI-1 and related names may be trademarks of their respective owners. This site is operated for uni-1ai.com; for billing, account terms, and support, use the links and email shown in the app.