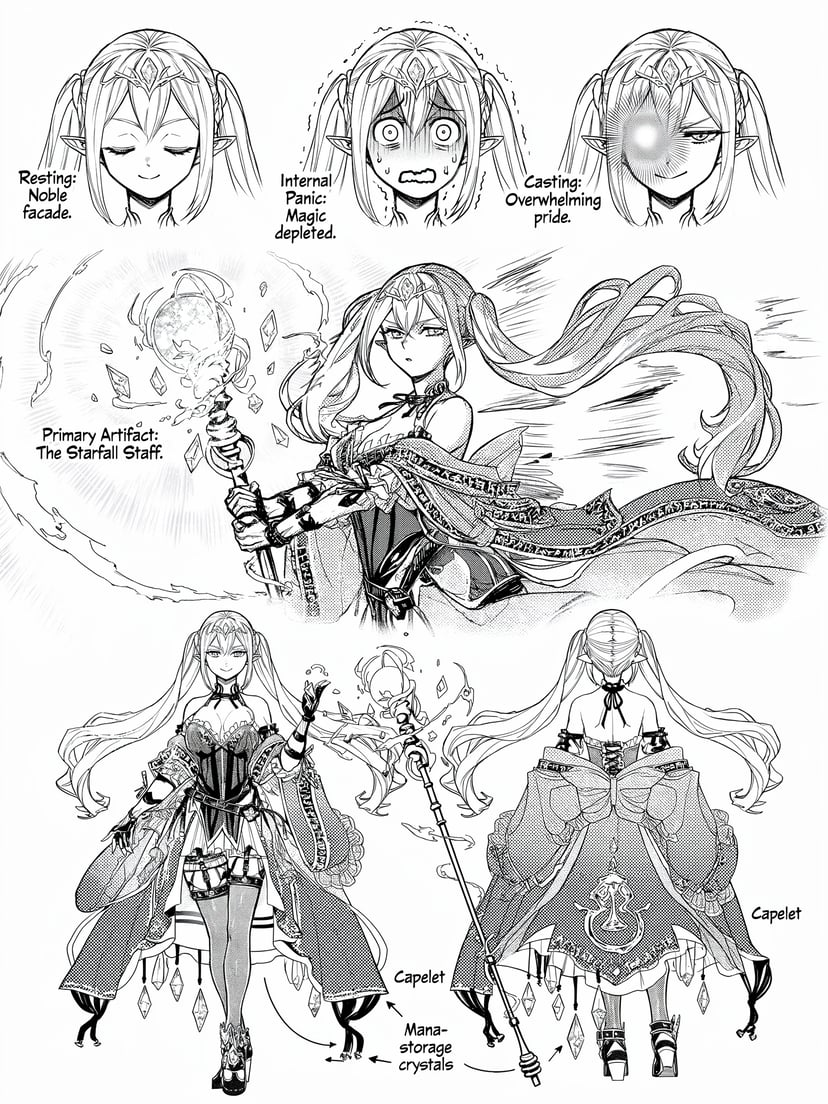
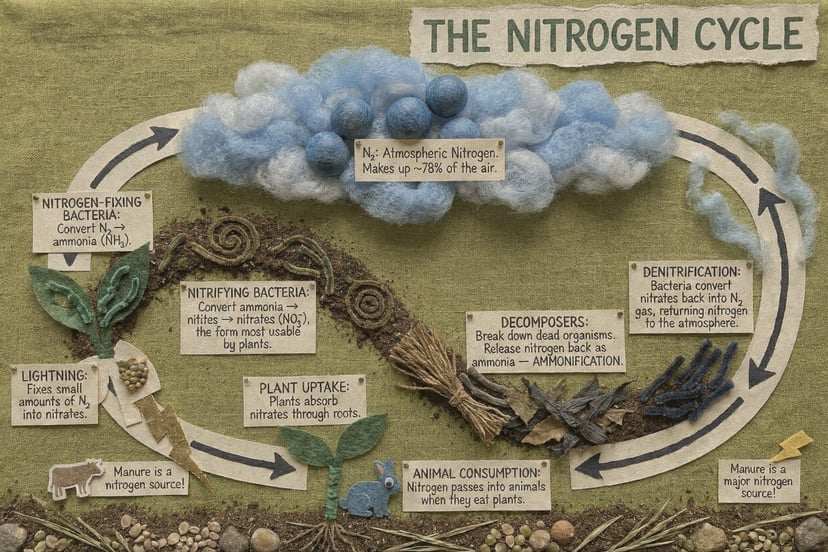
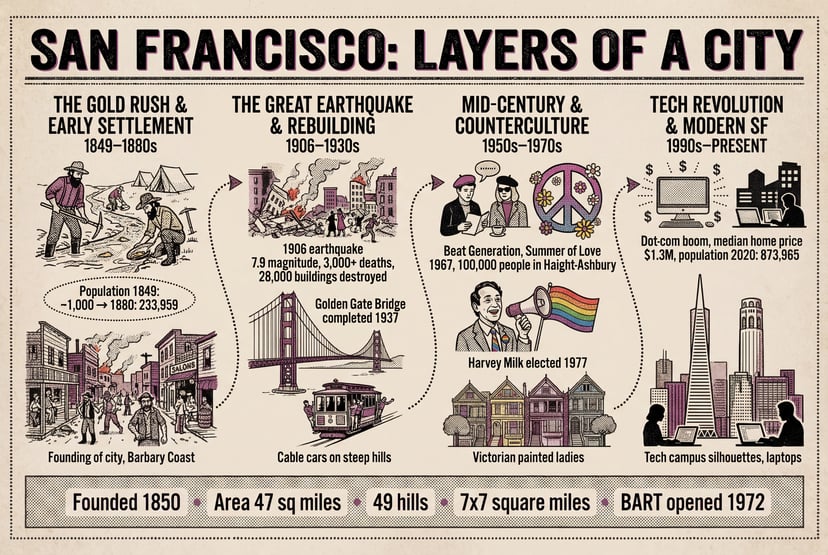
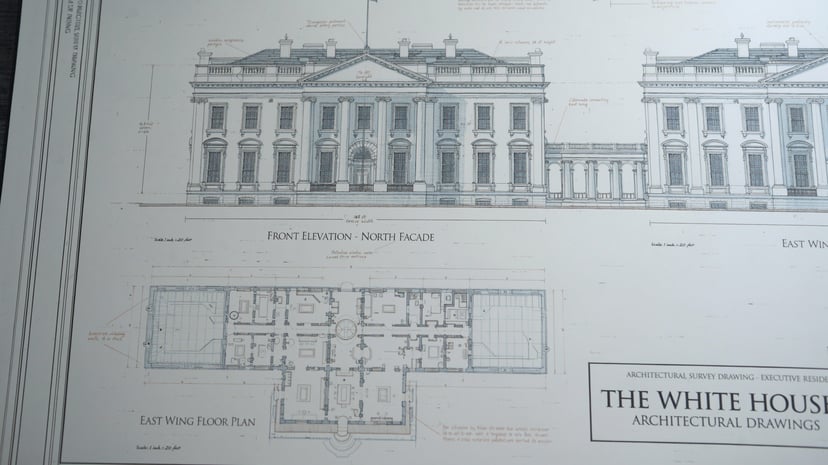
Weitere Beispiele
Infografiken, Diagramme, Morsecode und mehrsprachiger Text — strukturiertes Reasoning vor den Pixeln.



UNI-1 · Unified Intelligence
Beschreiben Sie unten, was Sie wollen — mit einem Klick generieren.
The full studio — generator, examples, and deep content — lives on a dedicated page so this homepage stays lightweight and fast.
Nur Vorschau — Generieren öffnet das Studio und übernimmt Ihren Prompt.
Sample look

Illustrative frame. Actual output depends on your prompt and settings in the studio.
Features and availability may vary by region and product updates.
Showcase
Ausgaben desselben Modells — nutzen Sie den Generator oben für Ihren eigenen Prompt.
Weitere Beispiele
Infografiken, Diagramme, Morsecode und mehrsprachiger Text — strukturiertes Reasoning vor den Pixeln.
Die nächste Evolution
Ein neues Paradigma für KI-Bildgenerierung
2026 erstmals veröffentlicht, ist UNI-1 das erste große Bildmodell, das visuelles Reasoning und Bildgenerierung in einer einheitlichen Architektur verbindet.
Klassische Pipelines koppeln ein Sprachmodell an einen separaten Bildgenerator — bei jeder Übergabe entstehen Kontextlücken. UNI-1 reduziert Modallücken und ermöglicht kohärentere mehrstufige Workflows.
UNI-1 kann strukturiertes internes Reasoning vor und während der Bildsynthese ausführen — Anweisungen zerlegen, Constraints lösen, Komposition planen, bevor ein Pixel gerendert wird.
Alltagssinn-Szenenvervollständigung, räumliches Reasoning, plausible Transformation — es folgt nicht nur Prompts, es versteht sie.
Mehrere Fotos zu einer neuen Komposition verschmelzen — Porträts, Objekte oder Umgebungen aus getrennten Quellen in einer Szene.
Kulturbewusste Generierung über globale Ästhetik, Memes, Manga — Nuancen, die generische Modelle verpassen.
Alltagssinn-Szenenvervollständigung, räumliches Reasoning, plausible Transformation — es folgt nicht nur Prompts, es versteht sie.
Mehrere Fotos zu einer neuen Komposition verschmelzen — Porträts, Objekte oder Umgebungen aus getrennten Quellen in einer Szene.
Mit einem Satz eine Entwicklungssequenz von Kindheit bis Alter unter fester Kamera — kausale Logik wie körperliches Altern automatisch.
Subjekte über mehrere Runden verfeinern, Kontext behalten, 76+ Stile, Skizzen und visuelle Anweisungen, Identität/Pose aus Referenzfotos.
Kulturbewusste Generierung über globale Ästhetik, Memes, Manga — Nuancen, die generische Modelle verpassen.
Komplexe Zeichen inkl. Redewendungen und Nicht-Latein — praktisch ohne Tippfehler, präziser als die meisten Konkurrenten.
Auf Reasoning-Benchmarks vor Imagen 3 und GPT Image 1, bei Objekterkennung nahe Gemini 3 Pro, bei hoher Auflösung etwa 10–30 % günstiger.
State-of-the-art auf RISEBench für reasoning-informierte visuelle Bearbeitung über zeitlich, kausal, räumlich und logisch.
Erster Platz im menschlichen Elo für Gesamtqualität, Stil & Bearbeitung, Referenzgenerierung; zweiter bei Text-zu-Bild.
Die Nur-Verstehen-Variante erreicht 43,9 auf ODinW-13 — das vollständige Modell mit Generierung 46,2. Die 2,3 Punkte zeigen: Bilder zu erlernen verbessert messbar das Verstehen. Das bestätigt die Kernthese: Vereinigung ist ein Leistungsmultiplikator.
Bei 2K kostet Text-zu-Bild etwa $0,09 pro Bild — verglichen mit $0,101 (Imagen 3) und $0,134 (Imagen 3 Pro).
Mehr Leistung. Weniger Kosten. Keine Kompromisse.
Preise in USD. Pro Bild basierend auf Billing-Tokens. Jedes Bild = 2.000 Billing-Tokens bei aktuellen Einstellungen.
Moderne Stacks erledigen End-to-End-Arbeit aus einem Brief — Text, Bild, Video, Audio — auf Basis von UNI-1, einem Decoder-only-Transformer, der Sprach- und Bildtokens in einem gemeinsamen Raum verzahnt, ohne Modellverkettung.
Diese Workflows planen und generieren modalitätsübergreifend und koordinieren mit anderen Frontier-Modellen — u. a. Google Veo 3, ByteDance Seedream, ElevenLabs-Stimmen.
Realfall: Eine 1-Jahres-$15M-Kampagne in 40 Stunden in günstige, lokalisierte Mehrländer-Versionen — mit strengem internem QC.
Vertrauen führender Marken:
Publicis Groupe, Serviceplan, Adidas, Mazda — im Agenturmaßstab.
Über klassische Diffusionsmodelle hinaus — rein autoregressives Paradigma. Reiner Decoder-Transformer wie GPT-Klassen.
Text und Bilder in einer verschlungenen Sequenz als Ein- und Ausgabe — strukturiertes Reasoning vor und während der Synthese.
Nähert sich dem intuitiven Schaffensprozess eines Architekten — Licht, Raum, Komposition gleichzeitig simulieren.
Ein vereinheitlichtes Verständnis- und Generierungsmodell, angekündigt am 5. März 2026. Visuelles Reasoning und Bildgenerierung in einem Decoder-only-autoregressiven Transformer.
UNI-1 reasoniert über Prompts vor und während der Generierung — kein reines Pattern-Matching, sondern Planung und Kontext.
Führt auf RISEBench in allen vier Dimensionen: temporal, kausal, räumlich, logisch.
Etwa $0,09 pro Bild bei 2K via API — 10–30 % günstiger als vergleichbare Google-Modelle.
Ja. Auf dieser Website kostenlos. API-Zugang rollt schrittweise aus — Enterprise: Support kontaktieren.
Multi-Referenz, 76+ Stile, mehrstufige Dialogbearbeitung, Skizze-zu-Bild, Identität/Pose, Alterungssequenzen — alles aus einheitlicher Reasoning-Architektur.
Die Hierarchie der Bildgenerierung hat sich verschoben. UNI-1 definiert neu, wie KI schaffen soll.
Unified Intelligence
UNI-1 und verwandte Namen können Marken der jeweiligen Inhaber sein. Diese Website wird für uni-1ai.com betrieben. Abrechnung, Kontobedingungen und Support über Links und E-Mail in der App.