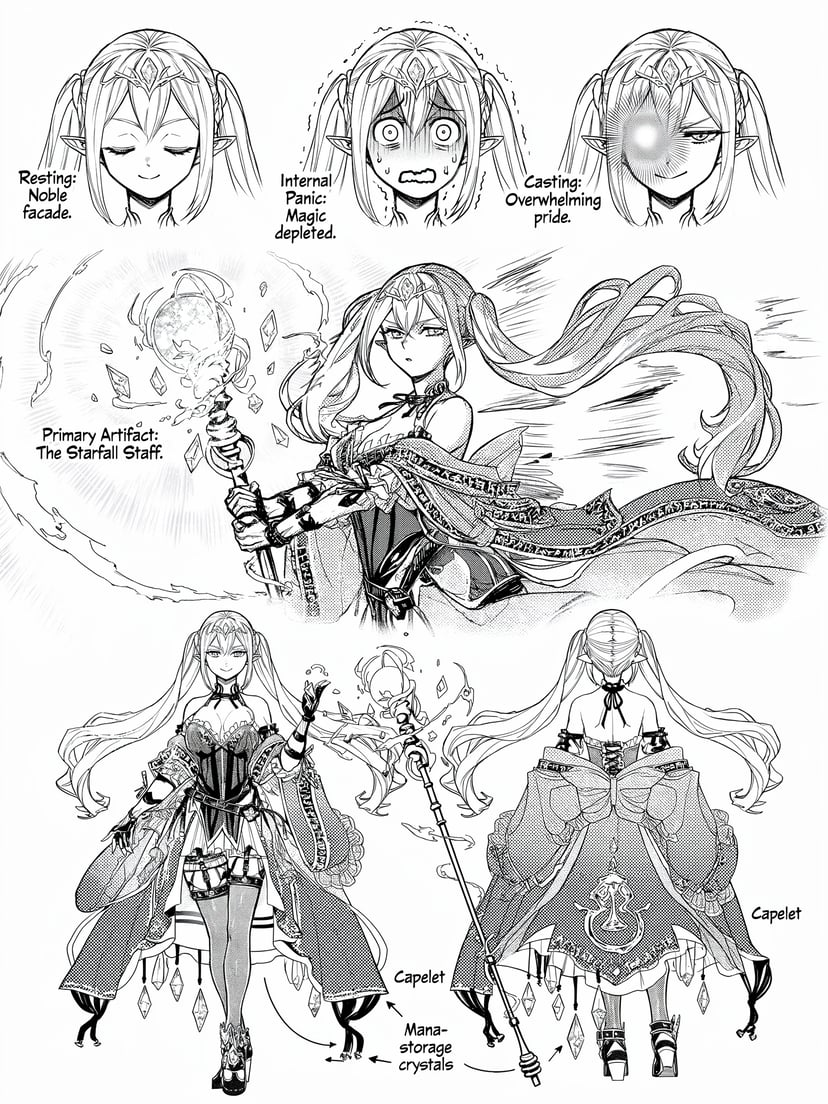
Mais exemplos
Infográficos, diagramas, código Morse e texto multilíngue — raciocínio estruturado antes dos pixels.



UNI-1 · Inteligência unificada
Descreva o que quer abaixo — gere com um clique.
The full studio — generator, examples, and deep content — lives on a dedicated page so this homepage stays lightweight and fast.
Apenas pré-visualização — Gerar abre o estúdio e preenche seu prompt.
Sample look

Illustrative frame. Actual output depends on your prompt and settings in the studio.
Features and availability may vary by region and product updates.
Showcase
Saídas do mesmo modelo — use o gerador acima com o seu prompt.
Mais exemplos
Infográficos, diagramas, código Morse e texto multilíngue — raciocínio estruturado antes dos pixels.
A próxima evolução
Um novo paradigma para geração de imagem com IA
Lançado pela primeira vez em 2026, UNI-1 é o primeiro grande modelo de imagem a combinar raciocínio visual e geração numa arquitetura unificada.
Pipelines tradicionais ligam um LM a um gerador separado e perdem contexto a cada passo. UNI-1 reduz lacunas e torna fluxos multironda mais coerentes.
Pode raciocinar de forma estruturada antes e durante a síntese — decompor instruções, resolver restrições e planear composição antes do primeiro pixel.
Completar cenas com senso comum, raciocínio espacial, transformações plausíveis — não só segue prompts, compreende-os.
Fundir várias fotos numa composição nova — retratos, objetos ou ambientes de fontes distintas numa cena coerente.
Geração sensível ao contexto global, memes, manga — nuances que modelos genéricos ignoram.
Completar cenas com senso comum, raciocínio espacial, transformações plausíveis — não só segue prompts, compreende-os.
Fundir várias fotos numa composição nova — retratos, objetos ou ambientes de fontes distintas numa cena coerente.
Com uma frase, gera evolução de infância à velhice com câmara fixa — lógica causal automática.
Refina em várias rondas mantendo contexto; 76+ estilos; esboços e instruções visuais; transferência de identidade/pose.
Geração sensível ao contexto global, memes, manga — nuances que modelos genéricos ignoram.
Caracteres complexos, expressões idiomáticas e scripts não latinos com quase zero erros — à frente da maioria dos rivais.
Supera Imagen 3 e GPT Image 1 em raciocínio, aproxima-se do Gemini 3 Pro em deteção, com custo ~10–30% menor em alta resolução.
Estado da arte no RISEBench em capacidades temporal, causal, espacial e lógica.
Primeiro no Elo humano em qualidade geral, estilo e edição, geração com referência; segundo em texto para imagem.
A variante só compreensão obtém 43,9 no ODinW-13; o modelo completo com geração 46,2. O ganho de 2,3 pontos mostra que aprender a criar imagens melhora compreendê-las — a unificação é um multiplicador de desempenho.
Em 2K, o preço API texto-para-imagem ronda $0,09 por imagem, contra $0,101 (Imagen 3) e $0,134 (Imagen 3 Pro).
Mais capacidade. Menos custo. Sem compromissos.
Preços em USD. Com base em tokens de faturação. Cada imagem = 2.000 tokens nas definições atuais.
Stacks modernos executam trabalho de ponta a ponta a partir de um brief — texto, imagem, vídeo, áudio — com UNI-1, um transformador apenas decodificador que entrelaça tokens num espaço partilhado sem encadear modelos.
Planeiam e geram coordenando com outros modelos de fronteira: Google Veo 3, ByteDance Seedream, ElevenLabs, entre outros.
Caso real: campanha internacional de um ano e $15 M transformada em versões localizadas de baixo custo em 40 horas — com QC interno rigoroso.
Marcas globais líderes confiam:
Publicis Groupe, Serviceplan, Adidas, Mazda — produção em escala de agência.
Para além da difusão clássica — paradigma autorregressivo unificado. Transformer apenas decodificador alinhado com modelos tipo GPT.
Texto e imagens numa sequência entrelaçada como entrada e saída — raciocínio estruturado antes e durante a síntese.
Aproxima-se do processo criativo intuitivo de um arquitecto humano — simula luz, dinâmica espacial e composição em simultâneo.
Modelo unificado de compreensão e geração anunciado a 5 de março de 2026. Combina raciocínio visual e geração num transformador autorregressivo apenas decodificador.
Raciocina sobre prompts antes e durante a geração — não é apenas correspondência de padrões.
Lidera no RISEBench nas quatro dimensões: temporal, causal, espacial, lógica.
Aproximadamente $0,09 por imagem em 2K via API — 10–30% menos que modelos Google comparáveis.
Sim. Neste site. O acesso API expande-se gradualmente — empresas: contactar suporte.
Composição multi-referência, 76+ estilos, edição conversacional multironda, esboço para imagem, transferência identidade/pose, sequências de envelhecimento — tudo numa arquitetura unificada.
A hierarquia da geração de imagem mudou. UNI-1 não só compete — redefine como a IA deve criar.
Unified Intelligence
UNI-1 e nomes relacionados podem ser marcas dos respetivos titulares. Este site é operado para uni-1ai.com. Faturação, termos de conta e suporte: links e e-mail na aplicação.