Plus d’exemples
Infographies, schémas, morse et texte multilingue — raisonnement structuré avant les pixels.



Chargement du générateur…
UNI-1 · Intelligence unifiée
Décrivez ce que vous voulez ci-dessous — générez en un clic.
Vitrine
Sorties du même modèle — utilisez le générateur ci-dessus pour votre propre prompt.
Plus d’exemples
Infographies, schémas, morse et texte multilingue — raisonnement structuré avant les pixels.
La prochaine évolution
Un nouveau paradigme pour la génération d’images IA
Publié pour la première fois en 2026, UNI-1 est le premier grand modèle d’image à combiner raisonnement visuel et génération dans une architecture unifiée.
Les pipelines classiques enchaînent un modèle de langage à un générateur séparé, créant des pertes de contexte. UNI-1 réduit ces écarts et permet des flux multi-tours plus cohérents.
UNI-1 peut raisonner de façon structurée avant et pendant la synthèse — décomposer les instructions, résoudre les contraintes et planifier la composition avant le premier pixel.
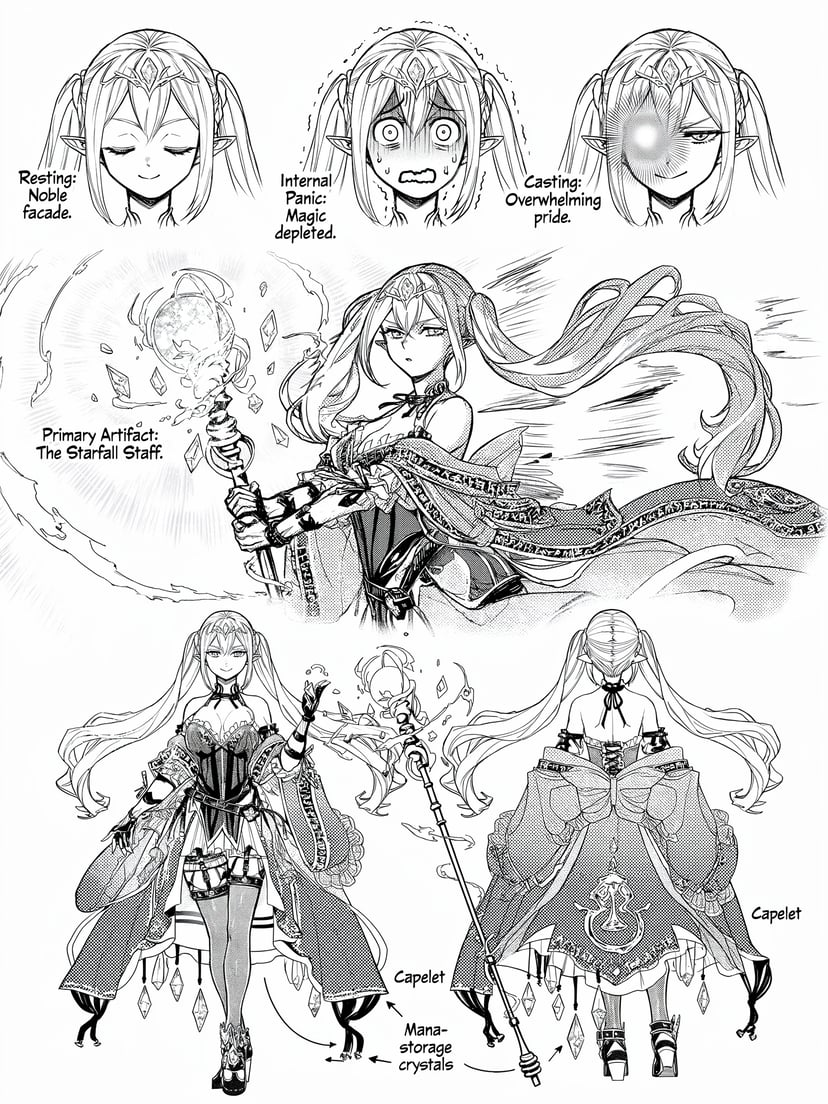
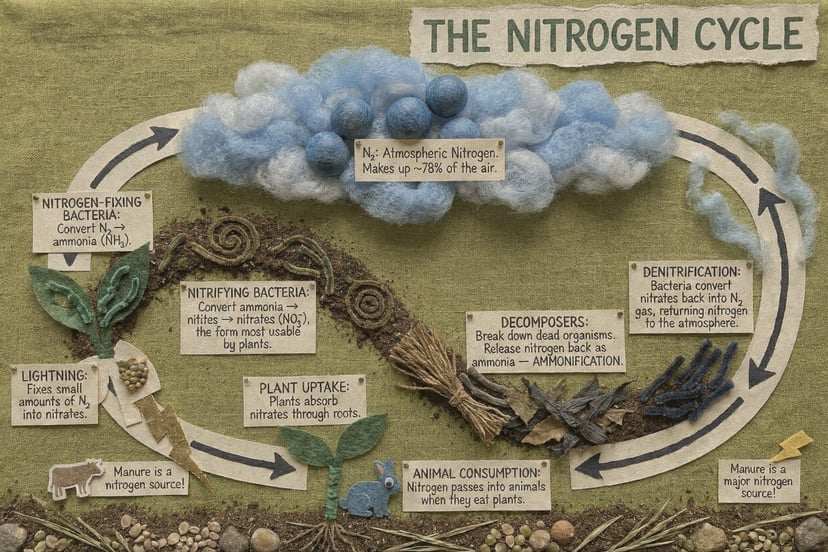
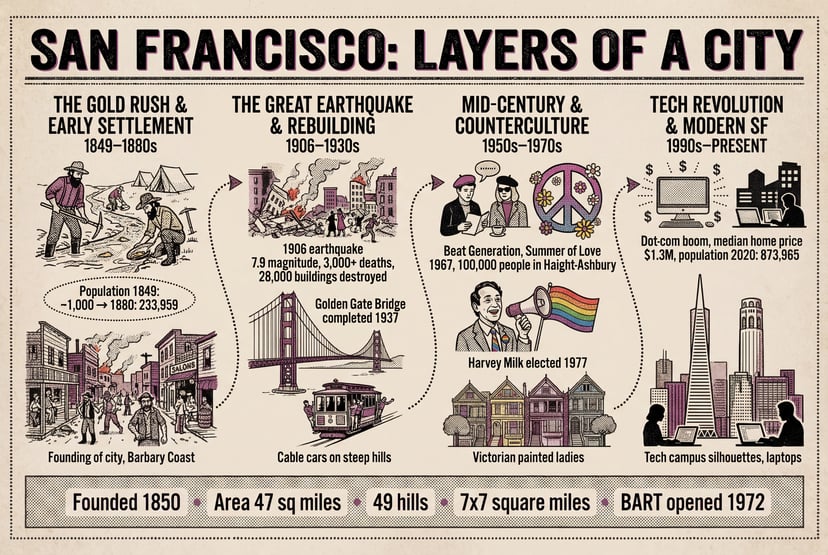
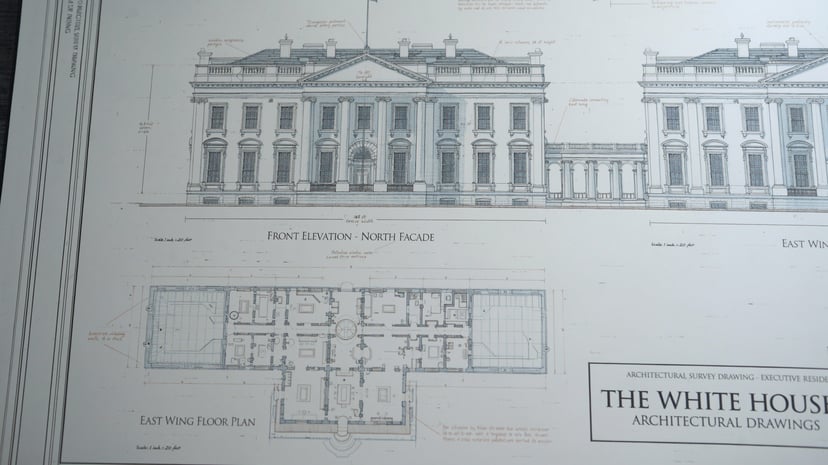
Complétion de scènes, raisonnement spatial, transformations plausibles — il ne se contente pas de suivre les prompts, il les comprend.
Fusionner plusieurs photos en une nouvelle composition — portraits, objets ou environnements de sources distinctes en une scène cohérente.
Génération sensible au contexte culturel mondial, mèmes, manga — nuances que les modèles génériques manquent.
Complétion de scènes, raisonnement spatial, transformations plausibles — il ne se contente pas de suivre les prompts, il les comprend.
Fusionner plusieurs photos en une nouvelle composition — portraits, objets ou environnements de sources distinctes en une scène cohérente.
Avec une seule phrase, génère une séquence d’évolution d’un personnage de l’enfance à la vieillesse sous un angle fixe — logique causale automatique.
Affine sur plusieurs tours en gardant le contexte ; 76+ styles ; croquis et instructions visuelles ; transfert d’identité/pose depuis des références.
Génération sensible au contexte culturel mondial, mèmes, manga — nuances que les modèles génériques manquent.
Caractères complexes, idiomes et scripts non latins avec presque zéro faute — au-delà de la plupart des concurrents.
Sur les benchmarks de raisonnement, il devance Imagen 3 et GPT Image 1, se rapproche de Gemini 3 Pro en détection d’objets, avec un coût ~10–30 % inférieur en haute résolution.
État de l’art sur RISEBench pour l’édition visuelle informée par le raisonnement.
Premier en Elo humain pour qualité globale, style et édition, génération par référence ; second en texte-à-image.
La variante compréhension seule obtient 43,9 sur ODinW-13 ; le modèle complet avec génération atteint 46,2. Le gain de 2,3 points montre qu’apprendre à créer des images améliore la compréhension — l’unification est un multiplicateur de performance.
En 2K, le prix API texte-à-image est d’environ 0,09 $ par image, contre 0,101 $ (Imagen 3) et 0,134 $ (Imagen 3 Pro).
Plus de capacité. Moins de coût. Sans compromis.
Prix en USD. Basés sur les jetons de facturation. Chaque image = 2 000 jetons avec les réglages actuels.
Les stacks modernes exécutent un travail de bout en bout à partir d’un seul brief — texte, image, vidéo, audio — sur UNI-1, un transformateur décodeur uniquement qui entrelace les jetons dans un espace partagé sans chaînage.
Ils planifient et génèrent en coordonnant d’autres modèles de pointe : Google Veo 3, ByteDance Seedream, ElevenLabs, etc.
Cas réel : une campagne internationale d’un an et 15 M$ transformée en versions localisées à faible coût en 40 heures — avec contrôle qualité interne strict.
Des marques mondiales leaders font confiance :
Publicis Groupe, Serviceplan, Adidas, Mazda — déployé à l’échelle des agences.
Au-delà de la diffusion classique — paradigme autorégressif unifié. Architecture Transformer décodeur uniquement alignée sur les modèles type GPT.
Texte et images dans une séquence entrelacée comme entrée et sortie — raisonnement structuré avant et pendant la synthèse.
Le résultat se rapproche du processus créatif intuitif d’un architecte humain — simuler lumière, dynamique spatiale et composition simultanément.
Modèle unifié de compréhension et de génération annoncé le 5 mars 2026. Combine raisonnement visuel et génération dans un transformateur autorégressif décodeur uniquement.
Il raisonne sur les prompts avant et pendant la génération — ce n’est pas du simple pattern matching.
Mène sur RISEBench sur les quatre dimensions : temporel, causal, spatial, logique.
Environ 0,09 $ par image en 2K via API — 10–30 % moins cher que des modèles Google comparables.
Oui. Sur ce site. L’accès API se déploie progressivement — entreprises : contacter le support.
Composition multi-références, 76+ styles, édition conversationnelle multi-tours, croquis vers image, transfert identité/pose, séquences de vieillissement — le tout depuis une architecture unifiée.
La hiérarchie de la génération d’images a changé. UNI-1 ne se contente pas de concurrencer — il redéfinit comment l’IA doit créer.
Unified Intelligence

UNI-1 et les noms associés peuvent être des marques de leurs détenteurs. Ce site est exploité pour uni-1ai.com. Facturation, conditions de compte et support : liens et e-mail dans l’application.