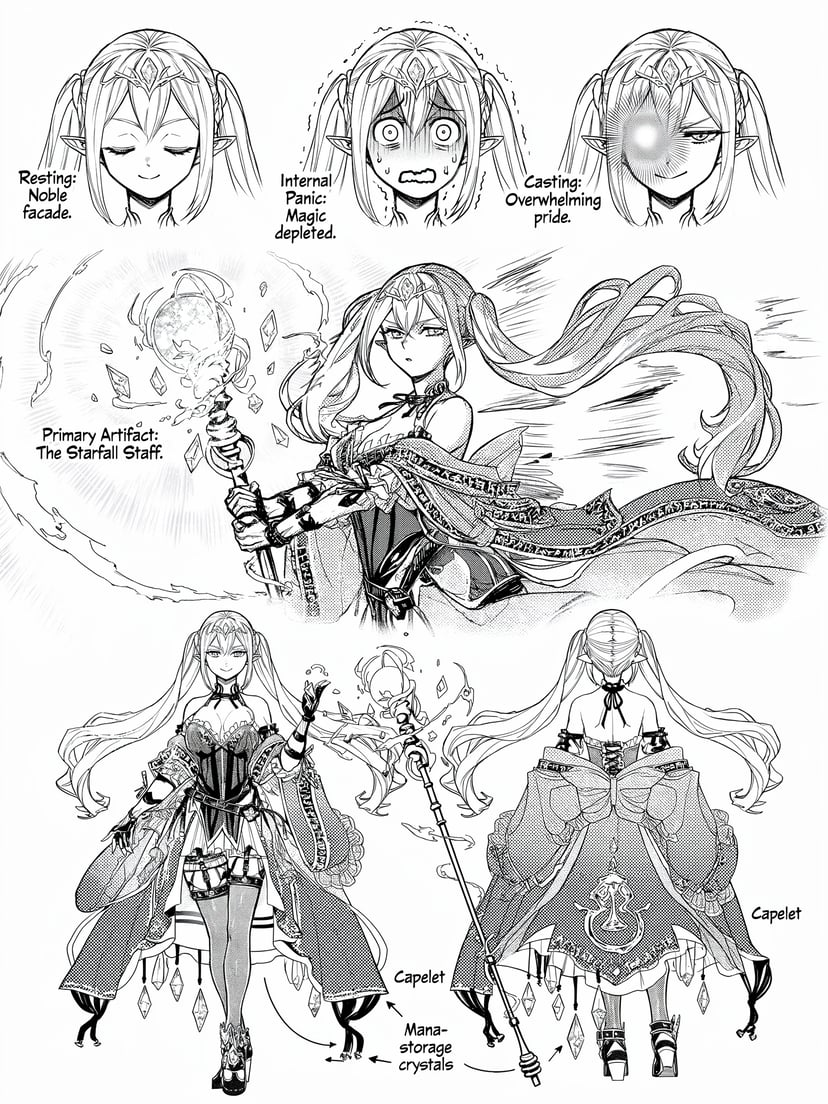
Ещё примеры
Инфографика, схемы, азбука Морзе и многоязычный текст — структурированное рассуждение до пикселей.
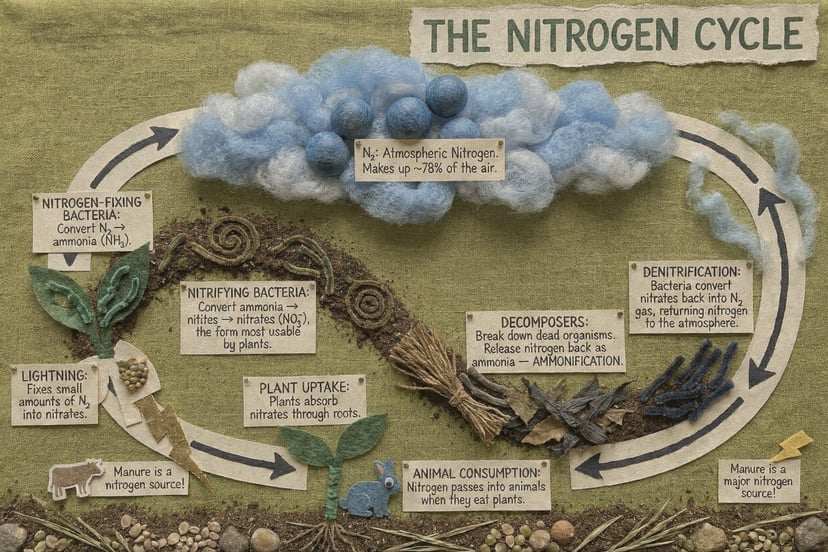
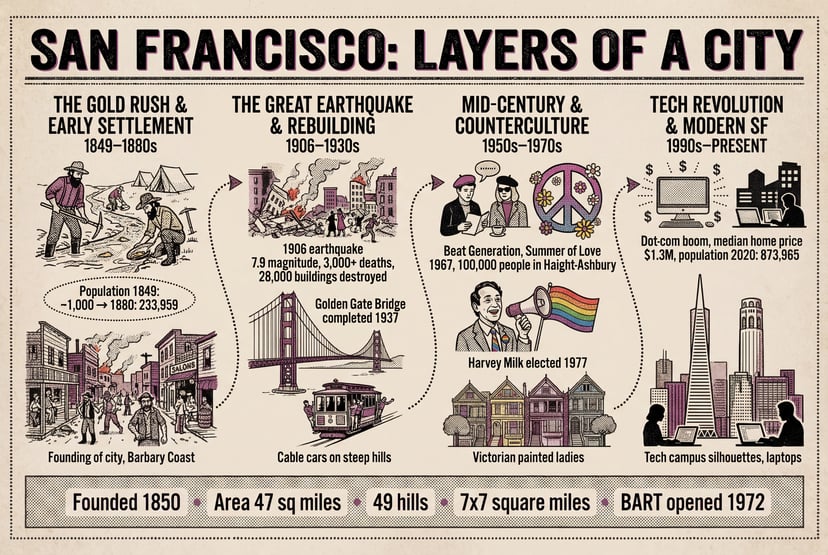
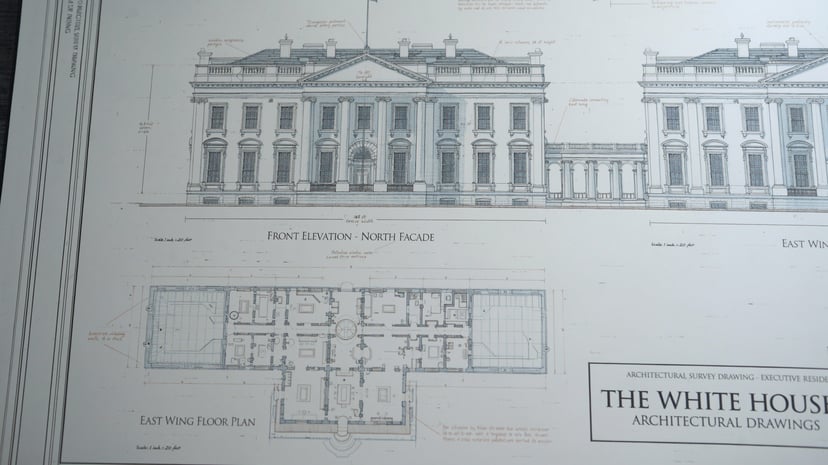



Загрузка генератора…
UNI-1 · Unified Intelligence
Опишите ниже, что нужно — сгенерируйте в один клик.
Галерея
Результаты той же модели — введите свой промпт в генераторе выше.
Ещё примеры
Инфографика, схемы, азбука Морзе и многоязычный текст — структурированное рассуждение до пикселей.
Следующий этап эволюции
Новый парадигм для генерации изображений
Впервые представленный в 2026 году, UNI-1 — первая крупная модель, объединяющая визуальное рассуждение и генерацию в единой архитектуре.
Традиционные пайплайны связывают языковую модель с отдельным генератором и теряют контекст на каждом шаге. UNI-1 сокращает модальные разрывы и делает многоходовые сценарии связнее.
UNI-1 выполняет структурированное внутреннее рассуждение до и во время синтеза — разбирает инструкции, снимает ограничения, планирует композицию до первого пикселя.
Дополнение сцен здравым смыслом, пространственное рассуждение, правдоподобные преобразования — не только следует промптам, но понимает их.
Сливает несколько фото в новую композицию — портреты, объекты или среды из разных источников в одной сцене.
Генерация с учётом глобальной эстетики, мемов, манги — нюансы, которые упускают общие модели.
Дополнение сцен здравым смыслом, пространственное рассуждение, правдоподобные преобразования — не только следует промптам, но понимает их.
Сливает несколько фото в новую композицию — портреты, объекты или среды из разных источников в одной сцене.
Одной фразой — эволюция персонажа от детства до старости при фиксированной камере — причинная логика без участия человека.
Уточняет субъект в нескольких раундах, сохраняя контекст; 76+ стилей; эскизы и визуальные указания; перенос личности/позы с референсов.
Генерация с учётом глобальной эстетики, мемов, манги — нюансы, которые упускают общие модели.
Сложные символы, идиомы и нелатиница с минимумом опечаток — точнее большинства конкурентов.
Лидирует над Imagen 3 и GPT Image 1 на рассуждениях, близок к Gemini 3 Pro в детекции объектов, примерно на 10–30% дешевле в высоком разрешении.
SOTA на RISEBench по временным, причинным, пространственным и логическим способностям.
Первое место в человеческом Elo по общему качеству, стилю и референсной генерации; второе в текст-изображение.
Вариант только с пониманием — 43,9 на ODinW-13; полная модель с генерацией — 46,2. Улучшение на 2,3 пункта показывает: учиться создавать изображения значит лучше их понимать — унификация умножает качество.
При 2K API текст-изображение около $0,09 за изображение против $0,101 (Imagen 3) и $0,134 (Imagen 3 Pro).
Больше возможностей. Меньше затрат. Без компромиссов.
Цены в USD. За изображение по биллинговым токенам. Каждое изображение = 2000 токенов при текущих настройках.
Современные стеки выполняют сквозную работу из одного брифа — текст, изображение, видео, аудио — на базе UNI-1, декодер-only трансформера с общим пространством токенов без цепочки моделей.
Планируют и генерируют, координируясь с другими frontier-моделями — Google Veo 3, ByteDance Seedream, ElevenLabs и др.
Реальный кейс: годовая кампания $15 млн за 40 часов превратилась в дешёвые локализованные версии — с жёстким внутренним QC.
Доверяют ведущие бренды:
Publicis Groupe, Serviceplan, Adidas, Mazda — производство агентского масштаба.
За пределами классической диффузии — чисто авторегрессивная парадигма. Чистый декодер-трансформер в духе GPT.
Текст и изображения — одна переплетённая последовательность как вход и выход — структурированное рассуждение до и во время синтеза.
Близко к интуитивному творчеству архитектора — свет, пространство и композиция одновременно.
Унифицированная модель понимания и генерации, анонсированная 5 марта 2026. Визуальное рассуждение и генерация в одном декодер-only авторегрессивном трансформере.
Рассуждает над промптами до и во время генерации — не шаблонное сопоставление, а план и контекст.
Лидер на RISEBench по четырём измерениям: время, причина, пространство, логика.
Около $0,09 за изображение в 2K через API — на 10–30% дешевле сопоставимых моделей Google.
Да. На этом сайте. API расширяется поэтапно — для enterprise пишите в поддержку.
Мульти-референс, 76+ стилей, многоходовое редактирование, эскиз-в-изображение, перенос личности/позы, последовательности старения — из единой архитектуры рассуждений.
Иерархия генерации изображений изменилась. UNI-1 не просто конкурирует — переопределяет, как ИИ должен создавать.
Unified Intelligence

UNI-1 и связанные названия могут быть товарными знаками правообладателей. Сайт работает для uni-1ai.com. Оплата, условия аккаунта и поддержка — ссылки и почта в приложении.